Bielefeld Institute for Bioinformatics Infrastructure




Omics Fusion
A web application to analyze and integrate microbial data from multiple omics sources


Stefan P. Albaum; Nils Kleinbölting; Bielefeld University, Bielefeld
Understanding a system as a whole often requires to consider its different levels and their connections [1]. For a ,biological organism‘ these levels are represented by: the genome (which genes are encoded on the DNA level), the transcriptome (what and how much is transcribed from the genome to mRNA), the proteome (what is translated into proteins/enzymes) and the metabolome (which metabolites are present – often as products of enzyme processing). The mere presence of a particular gene or allele, respectively, is not providing insights into a possible number of transcripts of this gene, and even less into the synthesis rates of the corresponding protein or the abundance of specific metabolites synthesized by specific enzymes. Many factors may influence this process. Moreover, synthesized proteins will in turn affect the actual metabolism of an organism. A holistic study of a living organism therefore has to consider all these different “omics” levels including a view into an organism's transcriptome, proteome and metabolome.
Omics Fusion has been developed to support researchers in the analysis of such datasets [2]. The web application provides a comprehensive portfolio of methods to analyze data from different levels of omics in an integrative manner. It is freely available to the public and provided following the software as a service paradigm. Omics Fusion has initially been designed for microbial data, but also has successfully been used for plant and other higher organisms data including human data.
Starting with the upload of data tables containing transcript counts, quantitative protein ratios or metabolome abundance values from high-throughput experiments users can draw on a collection of tools for integrative data analysis and data visualization to gain new insights into a biological system under investigation. This includes functionality to filter, normalize and transpose data and analyses such as variance and regression analysis to determine significantly differentially abundant transcripts, proteins or metabolites. Methods such as principal component analysis and t-SNE can provide an initial overview on the data by reducing its dimensionality and thereby increasing the interpretability.
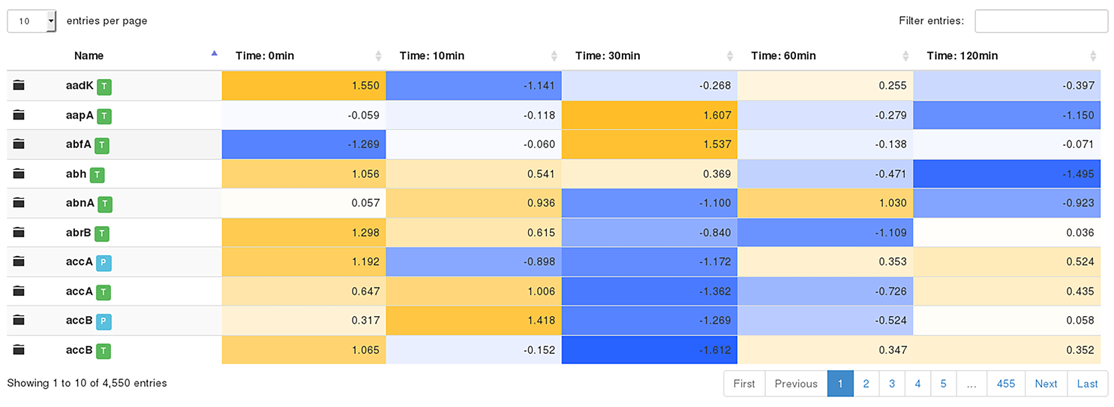
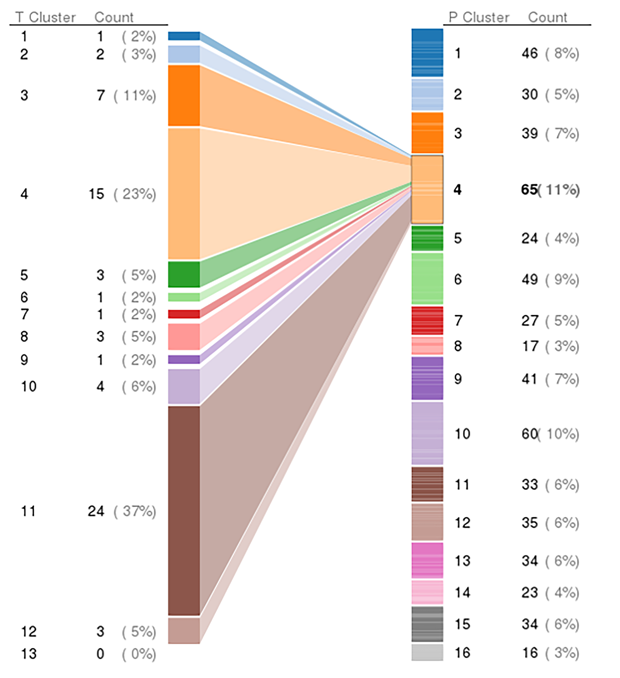
Omics Fusion places a particular emphasis on unsupervised learning methods. Cluster analysis, for example, allows to identify groups of transcripts, proteins and metabolites that show a similar pattern of expression or abundance. A common problem, in this regard, is the determination of an optimal number of clusters fitting to the data. Our software offers various means to apply cluster algorithms on the data and features a fully automated procedure to determine optimal clustering solutions. Furthermore, specialized cluster methods have been developed and allow, inter alia, the combined detection of transcripts and proteins that show similar patterns of abundance.
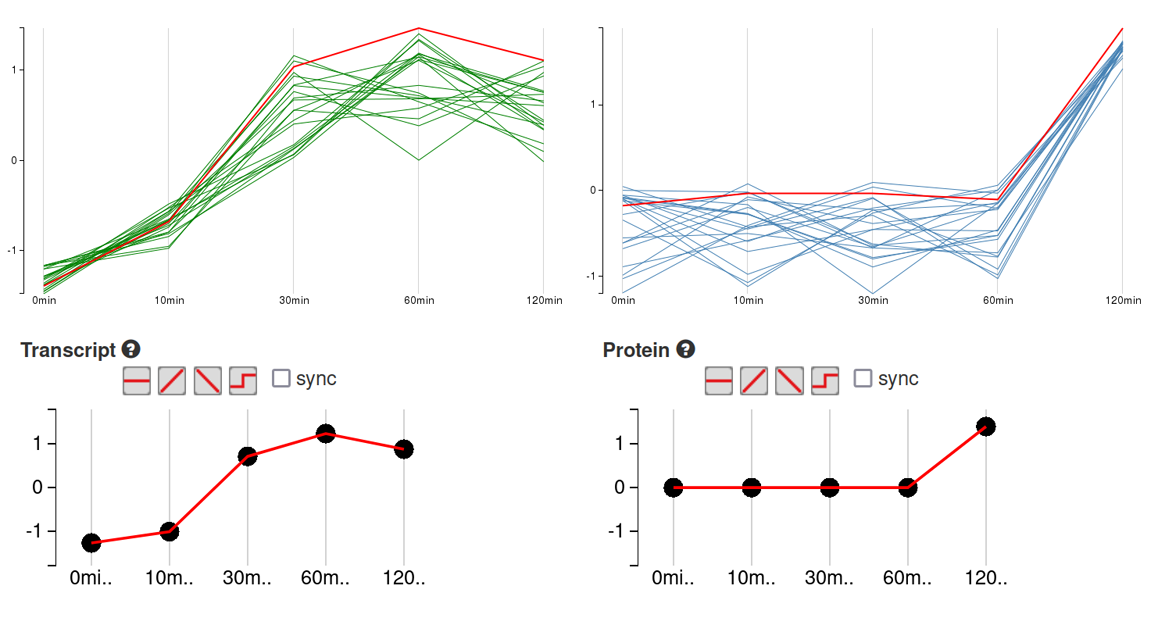
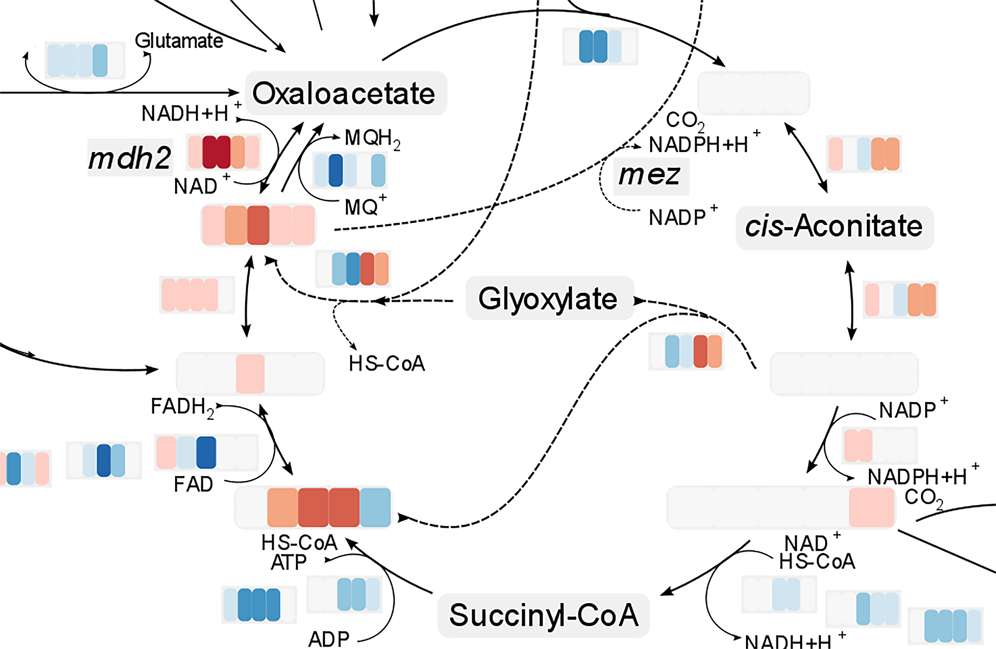
Extensive visualization methods enable explorative ways to better understand the data. An intuitive presentation is the combined mapping of transcript, protein and metabolome data on metabolic pathway maps. The tool box for visual and meaningful representation of data, moreover, contains scatter plots, box- and whisker plots and parallel coordinate plots. An important element for understanding biological data is the enrichment of the quantitative information by further descriptions of gene functions or metabolite characteristics and their role in an organism. For this purpose, Omics Fusion provides interfaces to common data repositories as provided by the NCBI [3] and the Uniprot consortium [4] to retrieve annotation data such as enzyme classifications, well-defined function descriptions or metabolic pathway associations. With this information, connections between the data may become visible that beforehand were not obvious.
Omics Fusion is continuously developed. Depending on the needs of the community, new methods are being integrated in the software or existing methods adapted.
References


[1] Zitnik et al. Machine Learning for Integrating Data in Biology and Medicine: Principles, Practice, and Opportunities. An international journal on information fusion, 2019. DOI: 10.1016/j.inffus.2018.09.012.
[2] Brink et al. Omics Fusion – A Platform for Integrative Analysis of Omics Data. Journal of integrative bioinformatics, 2016. DOI: 10.2390/biecoll-jib-2016-296.
[3] Benson et al. GenBank. Nucleic acids research, 2013. DOI: 10.1093/nar/gks1195.
[4] Uniprot Consortium. UniProt: the universal protein knowledgebase in 2021. Nucleic acids research, 2021.DOI: 10.1093/nar/gkaa1100.